Helping scientists share immutable sets of files generated from large scale, bioinformatics research
Datasets

Duminda Aluthgamage (Product Designer)
John Hill (Principal Engineer)
Nicholas Grosenbacher (Engineer)
Jay Hodgson (Engineer)
Kevin Boske (Principal Product Manager)
Team
Lead Product Designer
Feature Owner
My Role
Requirements gathering
Prototyping and testing
High fidelity Design
Implementation support
Documentation support
Evaluation
Roadmap
My Contribution
Products
The Opportunity
Scientists needed an efficient and scalable way of sharing large sets of files generated from collaborative bioinformatic research studies.
Background: Synapse
Synapse is an open source set of web, api and command line features that allow scientists to upload, organize, annotate, and share bioinformatic data. The core goal of Synapse is to curate bioinformatic data and make it FAIR (Findable, Accessible, Interoperable & Reusable).
Once this data exists within Synapse, it can be organized, used within the platform and with integrated applications, downloaded by others, extracted using programmatic workflows, connected with publications or presented in downstream resources. Before the introduction of Datasets, the core Entities in Synapse were Projects, Folders, Files, Views and Docker containers

Existing features and workflows within Synapse lacked the flexibility, finality and user experience needed to create and share large sets of files. Prior solutions within the platform only partially solved the problem and were workarounds that were not scalable.
Entity type
Limitations
Files within the ZIP archive cannot be accessed and used individually
Individual files do not benefit from Synapse features (provenance, versioning, annotation, wikis)
File (as ZIP archive)
Not possible to version a folder
Not easy to query files within a folder using annotations
Not scalable to create folders based on files in disparate locations
Folder
Not possible to download files from table
UI optimized for tables, (standard database feature), not file presentation
Table of File IDs
Built for the purpose of a dynamic “view” into one or more folders rather than a static/ immutable collection of items
Require the user to set a scope rather than ability to add and remove files across folders
UI is optimized for bulk annotation and querying based on annotations, rather than for representing sets for download
FileView
Core Use Cases & Scenarios
Large Consortium initiatives
Multiple labs or institutions collaborating. Researchers upload Data into separate projects and folders, and Sage Data Curators want to represent these as a single, immutable entity that can be versioned and shared in a Portal
After conducting internal research with stakeholders to gather requirements, it was decided that there are three, broad, related use cases which were optimizing for:
Personal Datasets
Researchers upload their own Data into one or more containers (projects/ folders), and they want to represent these as a single, immutable entity that can be connected to a publication, tool or programmatic workflow
Secondary Datasets [Future]
Researchers found a set of files within our platform (Portals/Synapse), and used these as part of their own work. They want to represent that set of files in a single, immutable entity to provide proper accreditation & reproducibility of work.
These use cases were specified further with multiple design scenarios which I created and work-shopped with stakeholders. Here are some examples of those scenarios:

Prototyping
I created a low fidelity interaction flow diagram to represent the different screens and features required to allow for these scenarios.
A systems design approach was required in order to incorporate several existing Synapse functions into Datasets, including metadata, governance, versioning & Digital Object Identifiers.
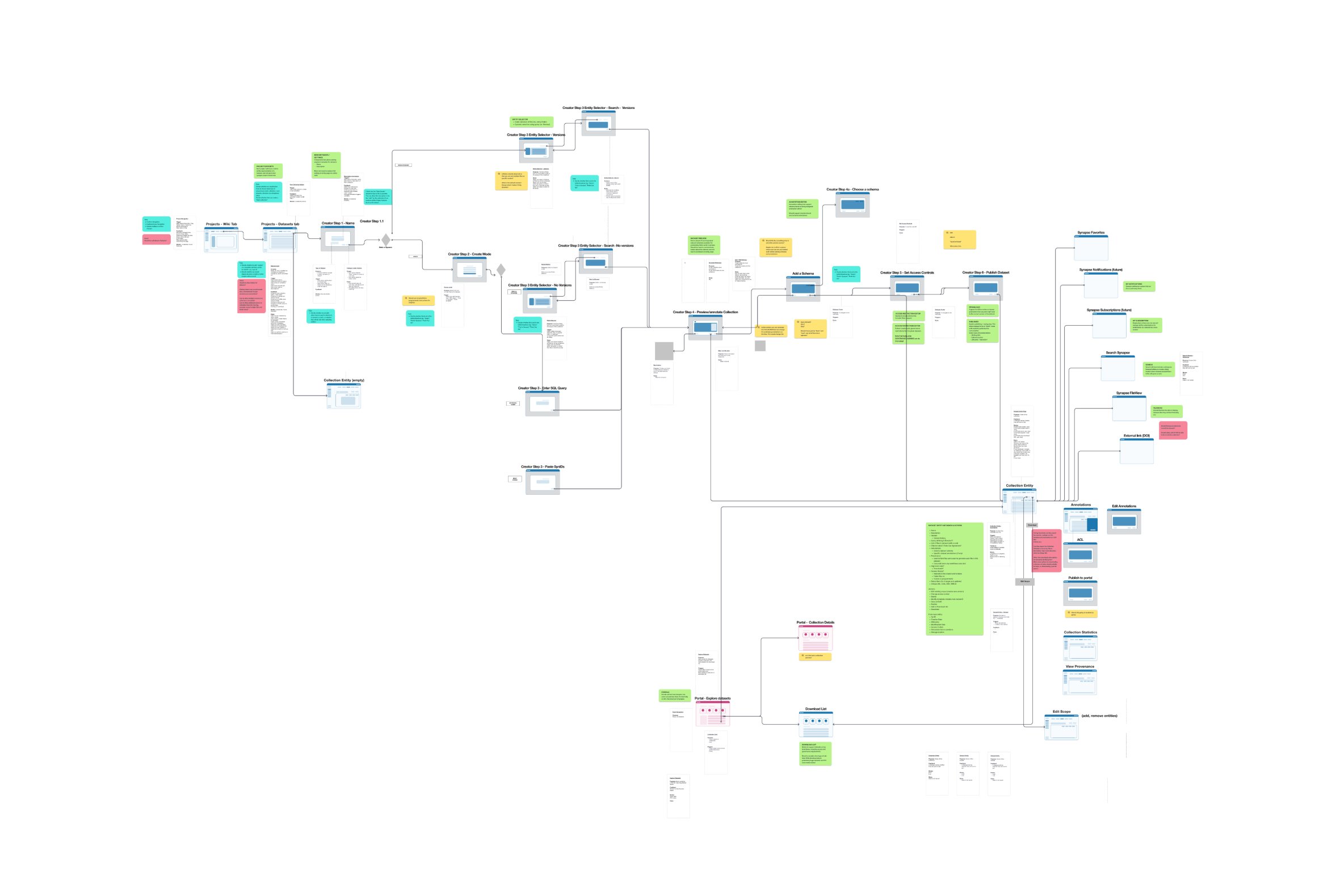

From here, I explored a number of design ideas and created early prototypes to be tested with users. These designs had to consider existing UX/UI patterns as well as all the key requirements. At the same time, our UI was going through a major overall including formalizing of our Design System. Changes had to be incorporated into the Datasets UI design dynamically.



Design & Implementation
I designed the final hi-fidelity flows and assisted engineers with the implementation of the MVP designs, performing QA, and creating a comprehensive Roadmap to track features as they were being developed, tested and released.

The Datasets Directory - View and create Datasets
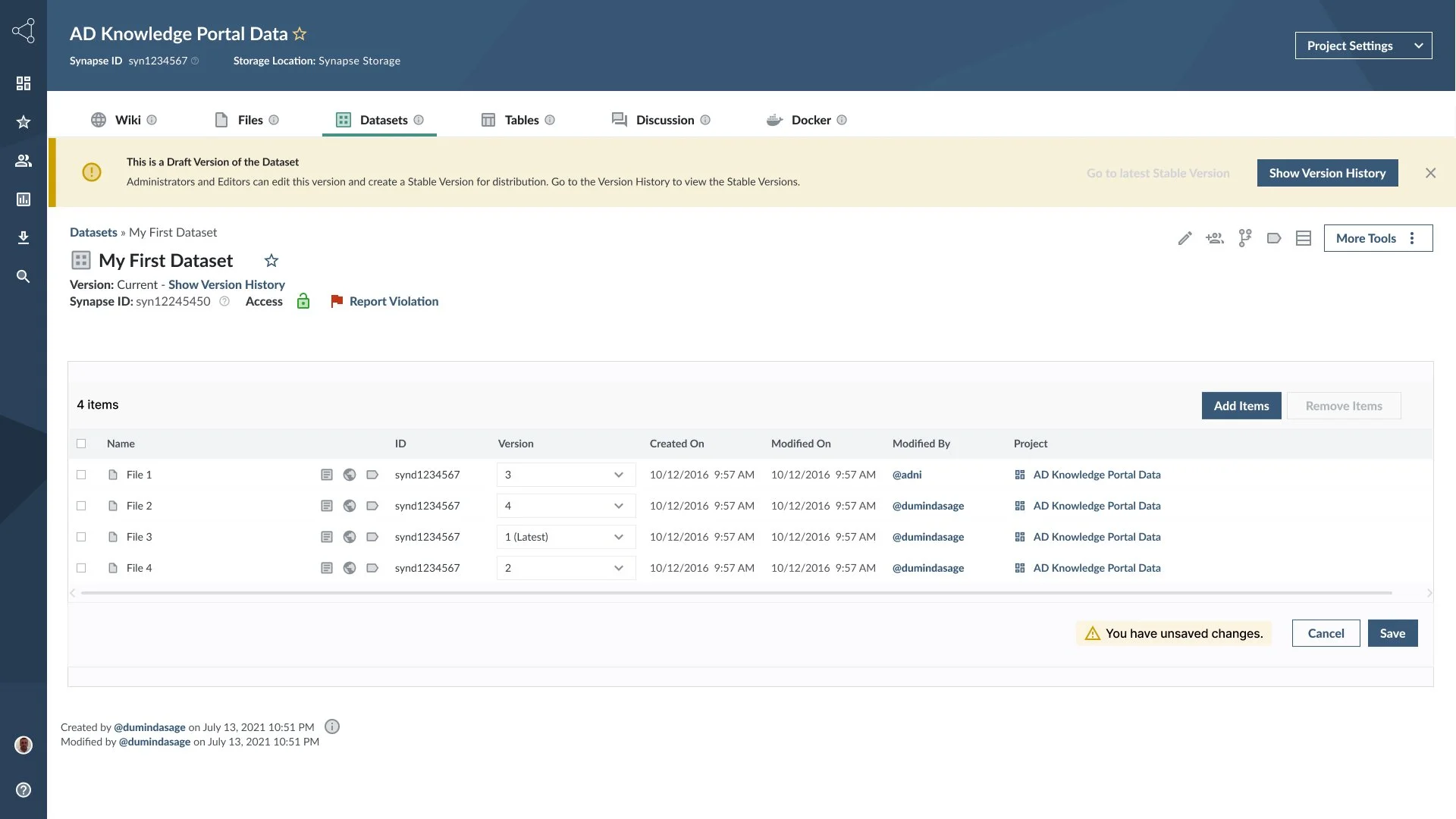
Dataset “Edit Mode” - trigger adding and removal of files

The Entity Finder - add and select files for the Dataset
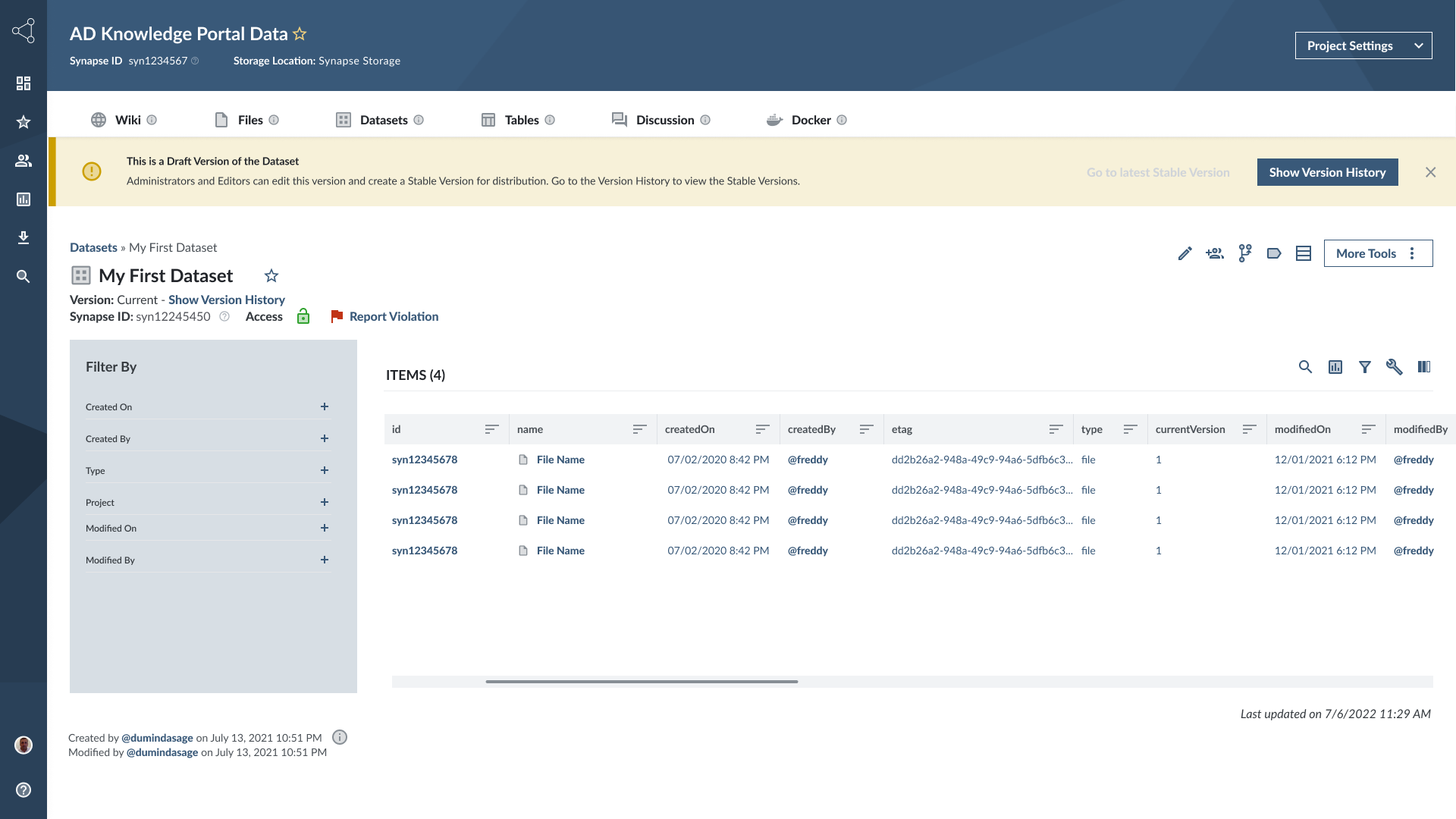
Video of the current Datasets implementation in Synapse
The Dataset Entity Page with items
The MVP went through additional evaluation with stakeholders.
This included another round of usability testing which I conducted in the live environment.
See evaluative research deck
Additional requirements
In order for this feature to be complete, I had to design how Datasets would appear within the knowledge portals. This involved using existing patterns within our design system to prototype the user flows and UI with feedback from Portals Product Managers.


Explore Datasets (in Portal)
Datasets Details (in Portal)
Next Steps
After the MVP, there were two major releases which continued to build on this feature. I wrote the initial draft of the Datasets Documentation, presented the feature to internal users & stakeholders, and also created a Use Case Spreadsheet to help prioritize ~45 new features that could be developed over the coming years.

Future use cases